ML学习笔记之————SVM

Adaboost指的是一种框架,可以讲若干个弱分类器级联成一个强分类器。对于这些弱分类器的选择上并没有任何限制,同时具有分类错误率上界随着训练增加而稳定下降,一般不会过拟合等的性质,应该说是一种很适合于在各种分类场景下应用的算法。

一个DSP的工程中往往有很多的.c执行文件,但是具体的执行顺序单从程序上的互相调用来看是理不清楚的,下面以一个具体的工程为例对DSP中工程的执行顺序进行分析,帮助更好的理解其整个芯片的运行机制。如有理解不对之处,敬请批评指正。
Cuda极大程度的方便了我们利用GPU并行处理来加快自己程序的运行速度, 但是大多情况下我们的程序是极为庞大的一个项目,只是利用cuda来加快其中某一块算法的运行效率,所以很多情况下是cpp文件来调用cu中的kernel函数。虽然cuda5.0之后可以直接从vs中生成现成的cuda项目,但是像这种通过cpp来调用cu文件的项目还是需要我们自己来进行配置的。
但是大多情况下我们的程序是极为庞大的一个项目,只是利用cuda来加快其中某一块算法的运行效率,所以很多情况下是cpp文件来调用cu中的kernel函数。虽然cuda5.0之后可以直接从vs中生成现成的cuda项目,但是像这种通过cpp来调用cu文件的项目还是需要我们自己来进行配置的。
尽量满足每个sm上面的最大线程数。
Cuda中对内核函数的调用<<< m , n >>>,m表示线程块的个数,n表示每个线程块的线程数, m个线程块构成一个线程格。M和n可以是一维的或者二维(三维)的,即使n是一维的,那么m也可以是二维的。
在cuda中,GPU中的SM(GTX650M有2个sm处理器)被GPU调度器把线程块逐个分配到SM上,每个SM同时处理这个被分配的线程块,但是每次每个时刻都只能处理一个warp线程束,由于有时会存在内存读取等操作导致等待,那么SM会转而处理其他的warp来掩盖这个延迟。
之前已经学过了DSP,但是前阵子机缘巧合,得到师兄指点,搞了一下实验室的嵌入式FD6000图像卡(FPGA+DSP6000),下面主要针对新学习的FPGA对其进行简要记录。
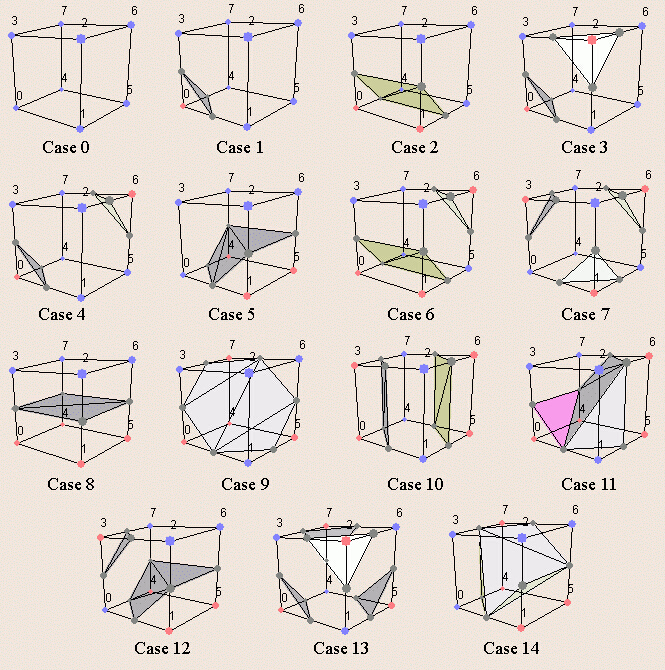
SDF三维表达仅仅包含对三维数据的表达,而并不是面片最终的表达。SDF是一种隐函数,如果需要对最终面片进行表达,需要通过marching cubes 算法提取各个体素的面片。
