Tracking————结构SVM
Tracking的两大类别
通俗的来说,在tracking领域目前主要分为生成模型和判别模型两个分支,生成模型主要是如何描述目标,也可以理解为如何提取目标的特征来表达目标模型,如稀疏表达,增量PCA,sift特征等都是生成模型,这类分支在生成目标模型后对目标的跟踪是基于匹配思想的,和目标模型匹配度越高的则认为是当前帧的目标。
而判别模型则是传统的分类器思想,判断当前目标是(1)或不是(0)目标。目前很多先进的方法是把这两个分支的方法融合到一块。
结构SVM
和正常的SVM算法不同,结构SVM只有输入向量X,正常的SVM是输入X对应一个输出向量Y。在结构SVM中,每个输入向量(图像的特征:灰度等)对应一个状态量state:{x,y,angel,scale..},但是这个状态量不作为输出特征。
在训练过程中,样本不在有正负样本的区别,所有的样本都是地位相同的,但是会有一个ground_truth。每个样本和这个ground_truth做相似性度量,得到相似度,越相似的样本评分越高,他们的排名就越靠前。在结构SVM中的优化目标和约束条件如下:
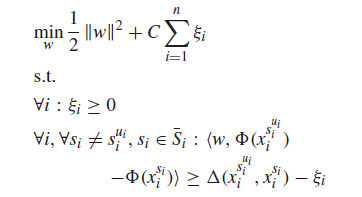
其中的Ф是核函数,Δ是这两个样本的相似性函数。因此结构SVM的最终优化是使得每个样本的排名都跟他们和ground_truth的相似度相吻合(只要排名顺序一致即可,相似性度量结果无关紧要)。
在测试阶段,给入一个向量X,结构SVM判断这些向量的排名rank,排名第一的向量认为是和当前样本X最相似的,因此把他的state:{x,y,angel,scale..}可以看做是当前样本的state。所以结构SVM能够直接获取特征X对应的state,而不再是传统的分类模型中的0,1,0,1….。
训练阶段正负样本的选取
在结构SVM中,没有正负样本之称,上一帧检测到的结果ground_truth,在其周围高斯采样样本,判断他们的相似性,得到rank,加入结构SVM中增量训练。
当前帧的结果怎么选取
根据上一帧检测到的结果ground_truth,在其周围高斯采样样本(这个采样和上一步训练阶段的采样可以相同也可以不同),对每个样本投入结构SVM中判断哪个样本能使SVM中训练阶段排名最高(上一帧的ground_truth)仍旧排名最高,那么这个样本就是这一帧的ground_truth。这一阶段采样越密,精度越高,但是耗时也就越长。
Tips:
文章[1]中的增量PCA的引入是为了消除特征之间的关联,把原始特征映射到子空间,之后又映射回原始空间来消除特征耦合,之后送入结构SVM中进行训练。
事实上,利用文章[1]提出的虚拟态state的框架,增量PCA可以替换成任意一个生成模型的算法。
参考:
【1】Online State-Based Structured SVM Combined With Incremental PCA for Robust Visual Tracking
